Designing Data Intensive Applications CH 7 - Part II 'Weak Isolation Levels'

Welcome again to the second part of chapter 7 in Designing Data-Intensive Applications where we discuss isolation levels and different problems that can occur and their possible solutions.
Transactions can safely run in parallel if they don't touch the same data because neither depends on the other, concurrency issues only occur when one transaction reads data concurrently being modified by another transaction, or when two transactions try to modify the same data.
Concurrency bugs are hard to test, because usually they occur when you become unlucky with timing which may occur very rarely and which also is very difficult to reproduce.
Databases tried to hide concurrency issues from application developers by adding transaction isolation.
There are weak isolation levels which have a more optimistic approach and serializable levels which are pessimistic and come at a huge performance cost (we'll get into that later)
Having a very good understanding of concurrency and the underlying problems it causes can help you a lot in building reliable and correct applications.
To start things off we'll look into several weak (non serializable) isolation levels that are used in practice and discuss in detail what kinds of race conditions can and cannot occur, so let's start!
Read Committed
This is the most basic level of isolation and basically makes 2 guarantees
When reading from the database you will only see data that has been committed which basically guarantees prevention of dirty reads which is when a transaction updates a certain value without committing and another transaction sees that update
When writing data you will only override committed data which means no dirty writes "dirty writes basically changing a value that was not committed yet so overriding an already changed value basically"
Dirty writes are a big problem and preventing them saves us from a lot of problems that can occur.
How is read committed really implemented? Preventing dirty writes are done by acquiring row level locks, when a transaction wants to change a certain row, we acquire a lock on it, and then releases the lock when the transaction is either committed or aborted.
Preventing dirty reads firstly was done by the same method, acquiring a lock, when a transaction wants to read a row it acquires a lock and releases it immediately after reading but acquiring read locks doesn't work well in practice because long running write transactions can make a read operation wait for a long time until it has access to the lock. This slows down the read operation and would slow the whole response all together. For this reason most databases now prevent dirty reads by remembering the old committed value and the new value in the current transaction that currently holds the write lock, while the transaction is ongoing any other read transactions will still get the old value. Only when the write transaction commits any read operations get the new value. This allows write operations not to block read operations and vice versa.
Snapshot Isolation and Repeatable Read
As good as read committed appears to be, some problems still might occur which might really mess up your data.
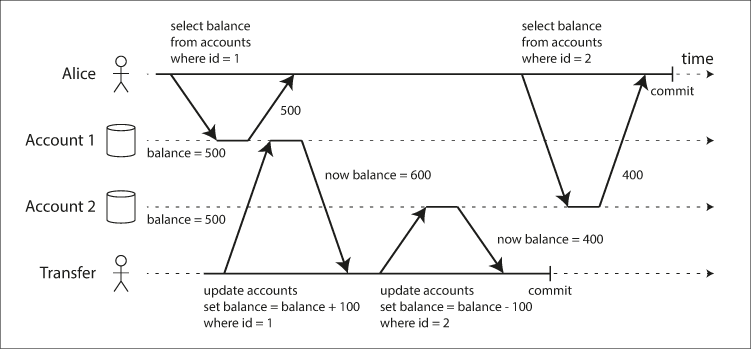
Check out the image above, Alice has 1000$ savings at a bank split across 2 accounts with 500$ each, now a transaction transfers 100$ from one account to another, if she's unlucky enough to look at her account at the time of the transfer happening she may see one account balance at a time before the transfer started, and the other after the transfer has committed. This seeing a total of 900$ instead of 1000$ so now 100$ vanished into the air.
This is usually called non repeatable read or read skew In Alice's case its not really a lasting problem, she can just refresh and she'll get the updated values. But the problem arises in other operations such as:
Backups; when taking backups they usually take hours, and the database keeps accepting read and write requests. Some parts of the backup might have old data which causes inconsistencies across the database
Analytic queries and integrity checks; These queries scan a large part of the database and they could return non sensical results of they scan the database at different points of time.
These problems can be solved using snapshot isolation, the idea is each transaction reads a consistent snapshot of the database that is the transaction sees all committed data to the start of the transaction even if it got changed during the transaction it will still see the old values. This is an optimistic isolation level approach.
How is snapshot isolation implemented? Like read committed, snapshot isolation uses write locks to prevent dirty writes, however reads don't require any locks. The key principle of snapshot isolation is readers never block writes and vice versa. The database must keep several committed versions of an object because various in progress transactions may need to see the state of the database at different points in time, because it maintains several versions of an object side by side. This technique is known as multi version concurrency control (MVCC)
Databases that implement MVCC use it for read committed level as well, to maintain different versions of an object (as we mentioned above), a typical approach is that read committed uses a separate snapshot for each query, while repeatable read uses a separate snapshot for the whole transaction.
Visibility rules for observing a consistent snapshot; when a transaction reads from a database, transaction IDs are used to detect which objects it can see and which are invisible. Visibility rules are:
- At the start of the transaction the database make a list of all the other transactions that are in progress(not yet committed or aborted) at that time and any writes that have been made by them are ignored even if it subsequently commits.
- Any writes made by aborted transactions are ignored
- Any writes made by a transaction with a later transaction ID( which started after the current transaction started) are ignored
- All other writes are visible to the applications queries.
How do Indexes in snapshot isolation? One option is to have the index simply point to all the versions of an object and require an index query to filter out any object versions that are not visible to the current transaction and when garbage collector removes the outdated versions their indexes can be removed as well. In practice, the implementation details really determine the performance of multi version concurrency control. For example; PostgreSQL has optimizations that avoid index updates if different versions of the same object can fit on the same page. Another approach used by CouchDB for example, is a append-only/copy on write approach, which doesn't overwrite pages of a tree when updated instead creates a new copy of each modified page, parent pages up to the root are copied and updated to point to their new children pages and any other page can remain immutable
So till now snapshot isolation seems great, but there still are some cases which won't really go as planned when it comes to snapshot isolation, one of them is called lost updates
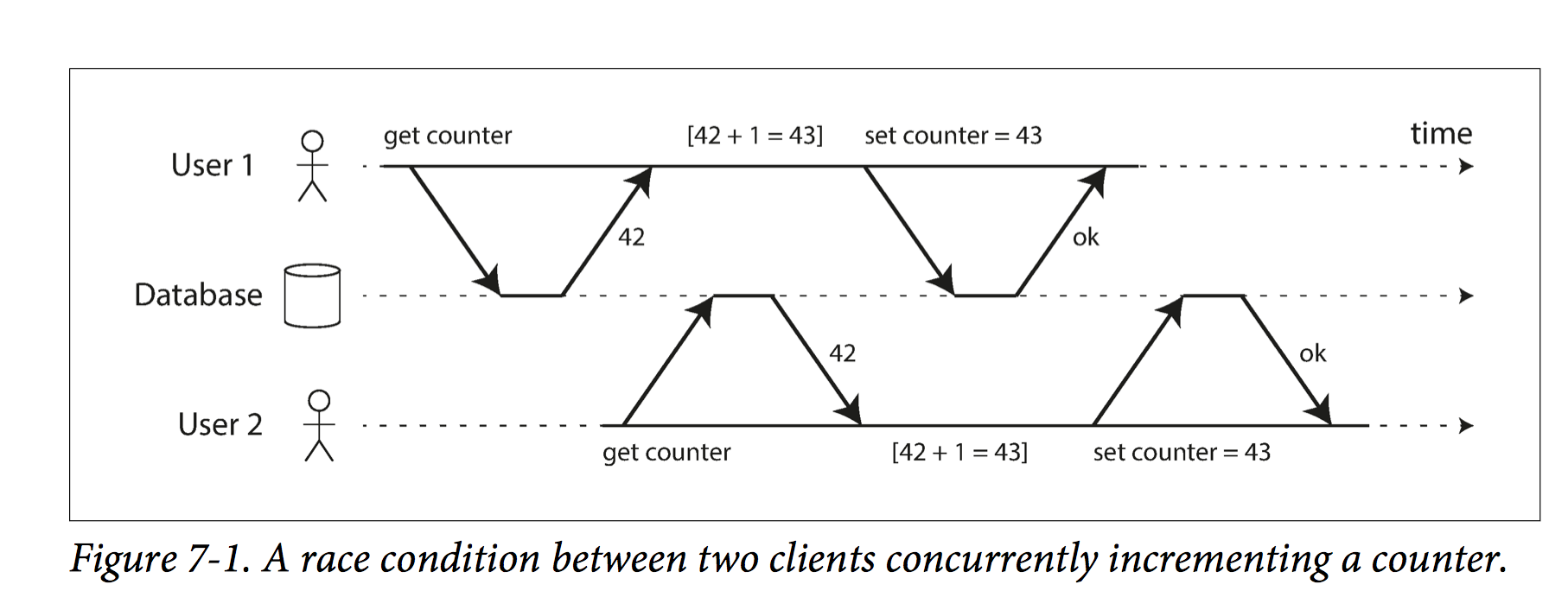
In the image above, two concurrent transactions increment a certain counter, but unluckily enough they both get the same value and increment based on that so they overwrite each other and a lost update occurs; unfortunately snapshot isolation doesn't really save you from these kind of problems, but luckily there are some things to keep in mind that will help prevent this problem from happening; The first solution is to use atomic write operations; this prevents the implementing of a whole read-modify-write cycle as a whole and does what is required basically in a single operation. For example the following is concurrency safe for most databases;
UPDATE counters SET value = value + 1 WHERE key = 'foo'
Atomic operations are usually implemented by taking an exclusive lock on the object and no other transaction can modify it until the update has finished. This technique is known as cursor stabillity, Another approach is to simply force all atomic operations to be executed in a single thread (serializable approach) e.g Redis
Explicit Locking If the applications database for some reason doesn't have atomic operations, another way is to explicitly lock the objects that are going to be updated, then the application can perform a read-modify-write cycle and if any other transaction tries to concurrently read the same object it is forced to wait until the first read-modify-write cycle to complete.
For example, consider a multiplayer game where several players move a figure concurrently, atomic operations won't be sufficient because you'll need to check and perform extra application logic to see if the move is correct according to the game's rules, this is a perfect use for explicit locking
BEGIN TRANSACTION;
SELECT * FROM figures
WHERE name = 'robot' AND game_id = 222
FOR UPDATE;
// for update locks all queried objects and releases the lock after transaction commits or aborts
// check if the move is valid then update the position of the piece that was returned by the select above
UPDATE figures SET position = 'c4' WHERE id = 1234;
COMMIT;
This will work but you need to think carefully about the application logic because it's easy to forget to add a lock somewhere and introduce a race condition.
Some databases automatically detect lost updates and force one transaction to retry when a lost update condition happens, e.g PostgreSQL
Compare-and-Set If databases don't have transactions, you'll sometimes find an atomic compare and set operation, it basically allows updates to occur if and only if the values of the object were not changed since you last read it. Otherwise it will be retried
Write Skew and Phantoms Imagine this example; you are writing an application for doctors to manage their on call shifts at a hospital, the hospital usually tries to have several doctors on call at any one time but it absolutely must have at least one doctor on call, Doctors can give up their shifts( if they are sick ) provided that at least one colleague remains on call in that shift. Now imagine Alice and Bob are two on call doctors, both are feeling unwell and both decide to request a leave, unfortunately they happen to click the button to go off call exactly at the same time, what happens next is illustrated in the figure below;
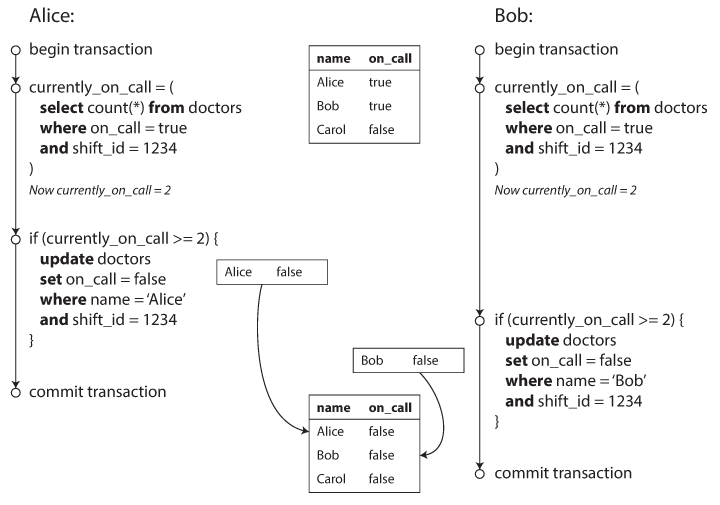
In each transaction the application first checks that two or more doctors are currently on call; if yes its safe for one doctor to go off call and since the database is using snapshot isolation both checks return 2 so both transactions proceed to the next stage, Alice updates her record to go off call as well as Bob and the transactions commit. And there is now no doctor on call so a main requirement of the application has been violated. This is usually called write skew which is really a generalization of the lost update problem, they usually occur when two transactions read the same objects and then update some of those objects, when you update the same object you got either a dirty write or a lost update.
There are less ways to prevent write skew than lost updates, from which are;
- Configuring constraints might be a good shout, which are enforced by the database (e.g uniqueness) however in order to satisfy that one doctor needs to be on call you'd need a constraint that involves multiple objects which is far complicated to implement
- Using serializable isolation which would force the two transactions to execute serially (one after the other) but if you can't do that then locking is your best bet.
Explicitly locking the returned rows from the first read operation would be as follows;
BEGIN TRANSACTION;
SELECT * FROM doctors WHERE on_call = true AND shift_id = 1234 FOR UPDATE;
UPDATE doctors SET on_call = false WHERE name = 'Alice' AND shift_id = 1234;
COMMIT;
More examples of write skew include a scenario where we have a meeting room and there is a booking system to it, there cannot be two bookings at the same time for the same room so when someone wants to book the room you would check for conflicting bookings first if none are found then proceed to create the meeting.
BEGIN TRANSACTION;
SELECT COUNT(*) FROM bookings WHERE room_id = 1234 AND end_time > time AND start_time < time;
// if the previous query returned zero
INSERT INTO bookings(room_id, start_time, end_time, user_id)
VALUES etc..
COMMIT;
In this example, two people might check at the same time causing two bookings to be created at the same exact time. You'd need serializable isolation or materializing the conflicts as we will see later.
Claiming a username where for example a website has a restriction that usernames must be unique, if two users entered the same username at the same time we might end with two users having the same username, luckily enough a unique constraint on the database would solve this and some application code to retry the unlucky user would work perfect.
Generalizing write skew conditions 1 - A SELECT query checks whether some requirement is satisfied by searching for rows that match some search condition (at least two doctors on call, no existing bookings, etc.) 2 - Depending on the result of the first query, the application code decides how to continue 3 - If the application decides to go ahead, it makes a write (INSERT, UPDATE or DELETE) to the database and commits the transaction
The effect of this write changes the precondition of the decision in step 2, If you were to repeat the SELECT of step 1 after committing the write you'd end up with different results because the write changed the set of rows matching the search conditions
The effect where a write in one transaction changes a result set of search query in another transaction is called a phantom
Now back to the bookings problem, previously in the doctors problem we were able to attach locks on the number of on_call doctors at a given time which would technically never return zero it would return at least 1 doctor. But in the bookings problem what if there are no bookings? what will we attach the lock at if there are no rows available from the search query? Well this is were materializing conflicts comes in place.
Materializing Conflicts artificially introduces a lock to the database, We could create a table of time slots and rooms and each row in this table corresponds to a particular room for a particular time period (say 15 minutes). You create rows for all possible combinations of rooms and time periods ahead of time, e.g for the next 6 months.
Now a transaction that wants to create a booking can SELECT FOR UPDATE (lock) the rows in the table that correspond to the desired room and time period, After it has acquired the locks it can check for overlapping bookings (our normal procedure) and insert a new booking as before. This additional table can be percieved as a collection of locks which is used to prevent bookings on the same room and time range from being modified concurrently.
Although this solves the problem, but its considered kind of ugly to leak a concurrency control mechanism into the data model, not to mention that they're quite hard and error prone so using materialized conflicts should be your last resort if no alternative is possible. A serializable approach would be better in most cases.
This concludes part II 'Weak isolation levels' and all that remains now is the final part talking specifically about serializable isolation, a more pessimistic approach I would say.
Hope you learned something today from this article and if anyone has any article ideas or some information they would like to share let me know in the comments section below! See you in the next one.




