Navigating the Jungle of Distributed Systems: A Guide to ZooKeeper and Leader Election Algorithms

Hello everyone! today's article is going to be going deep into Apache Zookeeper which is a popular open-source coordination service used mainly in distributed systems. We're going to be going through what it is, some of its use cases and a walkthrough example using Golang electing leaders and achieving consensus on a simple level.
What is Zookeeper?
It's simply an open-source coordination and synchronization service for distributed applications, It was originally developed by Yahoo! and is now maintained as part of the Apache Software Foundation. ZooKeeper provides a reliable and highly available way for distributed applications to synchronize and coordinate tasks in a distributed environment.
Zookeeper is based on a tree-like structure composed of nodes, called Znodes and it resembles a file system in many ways.
Znodes are the fundamental building blocks of the ZooKeeper data model. Each Znode can have associated data and metadata as well as children. These Znodes can represent various aspects of a distributed system, such as configuration settings, status information, locks, leader election, and more (we'll get into them later).
Each Znode is identified by a unique path within the hierarchy. Paths are similar to file system paths and consist of forward slashes ("/") to separate nodes. For example, "/app/config" represents a Znode named "config" located under the "app" node.
Znodes can store relatively small amounts of data (typically limited to a few kilobytes). This data is associated with the Znode and can represent configuration values, status information, or any other relevant data for a distributed application.
Zookeeper use cases
Zookeeper can be used in multiple cases including the following;
Configuration management — Managing application configuration that can be shared across servers in a cluster. The idea is to maintain any configuration in a centralized place so that all servers will see any change in configuration files/data.
Leader election — Electing a leader in a multi-node cluster. You might need a leader to maintain a single point for an update request.
Locks in distributed systems — distributed locks enable different systems to operate on a shared resource in a mutually exclusive way. Before updating the shared resource, each server will acquire a lock and release it after the update.
Manage cluster membership — Maintain and detect if any server leaves or joins a cluster and store other complex information of a cluster.
In this article, we'll go through code examples of a leader election (after I explain the algorithms) and a Manage cluster membership.
Zookeeper crash course
Before moving on to the fun stuff, let's give a quick introduction to zookeeper API, etc.
Zookeeper has different types of Znodes; ephermal, persistent, ephermal sequential and persistent sequential
Ephermal nodes live for as long as the session of the client that created it is still alive. For example if clientA decides to create an ephermal Znode and disconnected, zookeeper automatically deletes the created Znode.
Persistent Znodes always persist no matter what happens to the client. So even if the client disconnected the Znode will not get deleted.
By default creating nodes using zookeeper API creates persistent Znodes, All we need to do is pass the ephermal flag to create an ephermal one.
Ephermal Sequential nodes are ephermal Znodes but attached to it is a sequence number that increments every time a new sibling Znode gets created, so if any new sibling Znode of the same type is created, it will be assigned a number higher than the previous one.
Persistent Sequential are persistent Znodes with a sequential number attached as a suffix.
Clients can set a watch on Znodes and get notified if any changes occur, These changes could be a change in Znode data, a change in any of Znodes children, a new child Znode creation or if any child Znode is deleted under the Znode on which watch is set. This is very important in notifying applications that a change in the cluster occurred for it to act accordingly.
Zookeeper recipes refer to common design patterns or usage patterns that have emerged over time for solving specific distributed coordination and synchronization problems. These recipes provide guidelines and best practices for leveraging ZooKeeper's features to implement various distributed system components. These patterns help developers create reliable and scalable distributed applications.
Some of the common recipes include Leader Election, Distributed Locks, Configuration Management, Service Discovery and a lot more.
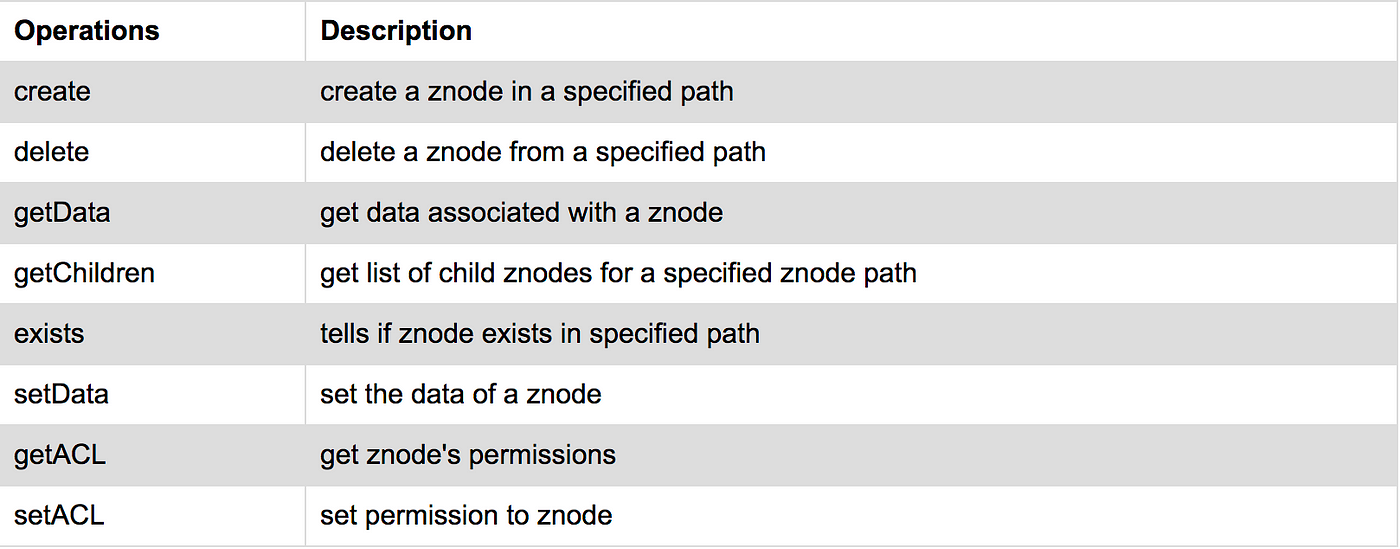
Some of the most used Zookeeper operations:
Leader Election in Zookeeper
Leader election is a critical concept in distributed systems and plays a pivotal role in ensuring coordination and reliability. In a leader election, a group of nodes or processes in a distributed system selects one of their members as the leader. The leader is responsible for making decisions, coordinating tasks, and maintaining the overall system's integrity. The other nodes in the group follow the leader's instructions and rely on them for guidance. Once that leader fails an election happens electing the new leader and so on. In our code example, we'll be doing writes only through the leader node, not the followers, Just like the single leader replication where the leader will be getting writes and replicating them to its followers.
There are several algorithms used in Zookeeper for leader election below are 3 of the most popular ones;
Write contention using ephermal Znodes
When a node boots up it creates a ephermal Znode for example /election/leader with its domain and port as Znode data if creating the Znode succeeds this node will be considered the leader, when another node boots up and attempts to create the same Znode it will get a node that already exists error.
All nodes will watch for changes in the /election Znode for any children addition or deletion.
If the leader fails for any reason a notification will be sent out to all watching nodes and therefore they will all try to write an ephermal Znode with the name /election/leader and the winning write is considered the leader.
To get the leader in the rest of the nodes we list the children of the /election Znode and get the data of the leader Znode which is the domain and port
The disadvantage of this approach is that once a leader goes down and notifications are sent to all follower nodes, each node tries to write the same Znode which causes performance issues as well as what is called a herd effect where nodes are just trying to write to Zookeeper which can cause huge performance issues
According to Wikipedia, the thundering herd problem occurs when a large number of processes or threads waiting for an event are awoken when that event occurs, but only one process can handle the event. When the processes wake up, they will each try to handle the event, but only one will win. All processes will compete for resources, possibly freezing the computer, until the herd is calmed down again.
Using Sequential Ephermal Znodes
This approach is all about Sequential Ephermal Znodes, Every node registers to Zookeeper under /election in a sequential manner, for example, if we have 3 nodes that register we will get the following: /election/leader-00001, /election/leader-00002, /election/leader-00003
These children are sorted and the smallest one is considered the leader. Meaning if leader-00001 fails leader-00002 is the new leader and so on.
All nodes watch for changes under /election and a notification gets sent out upon Znode addition or deletion. Servers fetch the leader by getting the children of '/election', sorting them and picking the smallest one
No unnecessary write requests are being made here we only fetch the children once a node addition or deletion occurs.
Use Sequential Ephermal but notify one server only
This approach is mainly for when you want to notify the server that became the leader only and not notify the followers. Meaning that the followers don't need to know who the leader is. This might happen if the leader server performs leader-specific tasks only.
Same process as above we create Sequential Ephermal Znodes in /election and the one with the least sequence will be considered the leader
The difference is we won't watch for /election node changes. Every node will listen only to the Znode sequentially before it.
Meaning '/election/leader-00002' node will watch for changes in /election/leader-00001. If leader-00001 got deleted only the next leader which would be leader-00002 would get notified and act accordingly.
Leader-00001 would have no watch set since there is nothing before it
This approach would only bother the server or node (same thing in this context)
that is going to become the new leader. It's useful when you don't want the followers to know who the leader currently is.
Distributed Locks in Zookeeper
Distributed locks are a way for multiple node coordination when changing a certain piece of data. This is to prevent possible data corruption and race conditions when mutually changing some piece of data. Data could be from a database for example.
A server will acquire the lock, update the data and release the lock for other servers to acquire. It's an exclusive lock mechanism (mutex kind of).
The mechanisms applied for leader election can be the same in distributed locks. Instead of /election we can have /lock and the only difference is after we finish the data update we need to delete the Znode created to free the lock.
This approach benefits from the use of Ephermal Znodes and is better than for example storing the key in Redis because when the node fails the Ephermal Znode will get automatically deleted freeing the lock and preventing any deadlock scenario which is a safer approach.
Group/Cluster membership
Maintaining group/cluster information is very easy using Zookeeper. We can watch the live nodes that are currently operating using Ephermal Znodes, watch all the nodes that are in the cluster anyway using Persistent Znodes and monitor for changes using watch and act accordingly.
We can have a Znode parent of /all_nodes and /live_nodes for all the nodes and the live ones specifically.
Group membership and leader election coding example
In this simple codebase using Golang. We aim to do the following:
Create a web server that connects to Zookeeper on server boot
The server gets registered as a live node and ads its election Znode as discussed above
I will spin up multiple instances of this server where each server should know who the current leader is and all the live nodes operating
We will have a simple POST API that creates a Person object
POST operations only go through the leader
The leader then replicates the Person to all its followers
Forgot to mention that when a server boots up it will sync its data from the leader node. The data will be kept in memory as it's just a simple example use case. This is the Git repo if anyone is interested
This is the main.go file. I'm using gin as a package for a quick, easy web server.
package main
import (
"flag"
"fmt"
"log"
"net/http"
"time"
"zookeeper/people"
"zookeeper/zookeeper_lib"
"github.com/gin-gonic/gin"
"github.com/go-zookeeper/zk"
)
func main() {
// instantiate a list of people empty
peopleList := []people.Person{}
r := gin.Default()
// when we run go run main.go we do -domain so we can run multiple instances
// ex: go run main.go -domain localhost:8000
domain := flag.String("domain", "", "")
flag.Parse()
// connect to my local zookeeper
conn, _, err := zk.Connect([]string{"127.0.0.1:2181"}, time.Second*2, zk.WithLogInfo(true))
if err != nil {
panic(err)
}
defer conn.Close()
//instantiate a new zkClient struct (we'll get to it)
zkClient := zookeeper_lib.NewZK(*domain, conn)
//register the Znode
zkClient.RegisterZNode()
// Use 2 go routines for watching live and election Znodes
go zkClient.WatchForLiveNodes()
go zkClient.WatchForElectionNodes()
// Sync any missing data from the leader
syncs := zkClient.SyncFromLeader()
peopleList = append(peopleList, syncs...)
log.Println("connected to zookeeper!")
// endpoint to fetch the people list
r.GET("/people", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{"data": peopleList})
})
// endpoint to create the person
r.POST("/people", func(c *gin.Context) {
// parse the request body to extract the person attributes
var person people.Person
if err := c.ShouldBindJSON(&person); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
return
}
// check if request is from leader from Request-From header
requestOrigin := c.GetHeader("Request-From")
if requestOrigin == "leader" {
// This server is a follower, just add the person to memory and return
peopleList = append(peopleList, person)
c.Status(http.StatusOK)
return
}
// if he is a leader then add to memory + send to followers
if zkClient.IsLeader() {
peopleList = append(peopleList, person)
go zkClient.SendToAllNodes(person)
c.Status(http.StatusOK)
return
} else {
// else the request came TO a follower, redirect it to a leader
fmt.Println("not leader, redirecting to leader")
leader := zkClient.Getleader()
zookeeper_lib.SendHTTPPostRequest(leader, person, true)
c.Status(http.StatusPermanentRedirect)
return
}
})
r.Run(":" + *port)
}
I explained using comments line by line as i found that it's easier to understand. Since most of the code are just method invocations we'll get to the ZKClient struct and explain everything in it.
The schema for the ZKClient struct is as follows;
const ALL_NODE_PATH = "/all"
const LIVE_NODE_PATH = "/live"
const ELECTION_NODE_PATH = "/election"
type ZkClient struct {
domain string
conn *zk.Conn
leader string
}
// Simply takes domain and connection and creates a zkClient struct
func NewZK(domain string, conn *zk.Conn) *ZkClient {
return &ZkClient{
domain: domain,
conn: conn
}
}
Now for the first method RegisterZNode
func (c *ZkClient) RegisterZNode() {
// create a PERSISTENT ZNODE in the ALL NODE PATH /all with domain as data
_, err := c.conn.Create(ALL_NODE_PATH+"/"+c.domain, []byte(c.domain), 0, zk.WorldACL(zk.PermAll))
if err != nil && err != zk.ErrNodeExists {
panic(err)
}
// create live EPHERMAL ZNODE /live with domain as data
_, err = c.conn.Create(LIVE_NODE_PATH+"/"+c.domain, []byte(c.domain), zk.FlagEphemeral, zk.WorldACL(zk.PermAll))
if err != nil {
panic(err)
}
// create EPHERMAL SEQUENTIAL ELECTION ZNODE IN /election with domain as data
_, err = c.conn.Create(ELECTION_NODE_PATH+"/leader", []byte(c.domain), zk.FlagEphemeral|zk.FlagSequence, zk.WorldACL(zk.PermAll))
if err != nil {
panic(err)
}
fmt.Println("registered znode with domain name: ", c.domain)
}
func (c *ZkClient) WatchForLiveNodes() {
// watch for live nodes in the /live zNode
// this watches the /live zNode for any children changes (or itself)
liveNodes, _, liveNodeEvents, err := c.conn.ChildrenW(LIVE_NODE_PATH)
if err != nil {
panic(err)
}
for {
select {
// live node events is a go channel this switch case blocks until data comes to the channel
case event := <-liveNodeEvents:
if event.Type == zk.EventNodeChildrenChanged {
// trigger watch again after event.
liveNodes, _, liveNodeEvents, err = c.conn.ChildrenW(LIVE_NODE_PATH)
if err != nil {
panic(err)
}
// i don't do anything with watching live nodes i just print them
fmt.Println("live nodes: ", liveNodes)
}
}
}
}
func (c *ZkClient) WatchForElectionNodes() {
// watch for the election zNode for leader election
electionNodes, _, electionNodeEvents, err := c.conn.ChildrenW(ELECTION_NODE_PATH)
if err != nil {
panic(err)
}
if electionNodes == nil {
panic("election nodes is nil")
}
fmt.Println("election nodes: ", electionNodes)
// a function that elects the new leader by getting all the children
// then it sorts them and takes the smallest one as the new leader
c.leader = electNewLeader(electionNodes, c)
for {
select {
case event := <-electionNodeEvents:
if event.Type == zk.EventNodeChildrenChanged {
electionNodes, _, electionNodeEvents, err = c.conn.ChildrenW(ELECTION_NODE_PATH)
if err != nil {
panic(err)
}
// re call the electNewLeader with the new children.
c.leader = electNewLeader(electionNodes, c)
}
}
}
}
// elects new leader
func electNewLeader(electionNodes []string, c *ZkClient) string {
// sorts children in /election
sort.Strings(electionNodes)
// picks first one
leader := electionNodes[0]
// gets its data (which is the server domain in our case)
data, _, _ := c.conn.Get(ELECTION_NODE_PATH + "/" + leader)
// prints and returns it
fmt.Println("leader is: ", string(data))
return string(data)
}
func (c *ZkClient) SyncFromLeader() []people.Person {
// fetch current leader from zookeeper (returns leader domain)
leader := c.getLeaderFromChildren()
if leader == "" || leader == c.domain {
// if no leader or current is leader skip
return []people.Person{}
}
// send get request to leader
url := "http://" + leader + "/people"
// build request
req, err := http.NewRequest("GET", url, nil)
if err != nil {
fmt.Println(err)
}
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
fmt.Println(err)
}
defer resp.Body.Close()
// parse response data and save.
respData := make(map[string][]people.Person)
err = json.NewDecoder(resp.Body).Decode(&respData)
if err != nil {
fmt.Println(err)
}
peopleList := respData["data"]
fmt.Println("synced from leader: ", peopleList)
return peopleList
}
// getLeaderFromChildren is the same logic as electNewLeader
// This sends the person object to all the follower nodes
func (c *ZkClient) SendToAllNodes(person people.Person) {
// gets the live nodes
allNodes, _, err := c.conn.Children(LIVE_NODE_PATH)
if err != nil {
panic(err)
}
// loop and send only to the follower ones(skip the leader node)
for _, node := range allNodes {
if node != c.domain {
fmt.Println("sending to node: ", node)
if !SendHTTPPostRequest(node, person, false) {
fmt.Println("failed to send to node: ", node)
}
}
}
}
// this function sends post requests to followers so they update their data
func SendHTTPPostRequest(domain string, person people.Person, Toleader bool) bool {
// build request
url := "http://" + domain + "/people"
req, err := http.NewRequest("POST", url, person.ToJSON())
if err != nil {
fmt.Println(err)
}
if !Toleader {
// this indicates that im not sending the request to a leader
// the request is to the followers then i will add the Request-From header
// the value of the header is set to leader to indicate that it came from leader node
req.Header.Set("Request-From", "leader")
}
// build the request and send it. Only return true if it succeeded
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
fmt.Println(err)
}
defer resp.Body.Close()
return resp.StatusCode == 200
}
Summary
Zookeeper for me was one of the things I had to get into sooner or later to understand what it does exactly. I wrote this article as a refresher for me in the future and to share what I came up with. I will link references below If you have any questions or any interesting facts you want to share feel free to reach me on any social media platforms. And as always till the next one!




