[Software Architecture: The Hard Parts][Chapter 5] Component Based Decomposition Patterns
![[Software Architecture: The Hard Parts][Chapter 5] Component Based Decomposition Patterns](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1698518766625%2F280ec157-223e-4828-8843-cee4a68c8561.jpeg&w=3840&q=75)
Introduction
Hello everyone! In this chapter, we'll discuss component-based decomposition patterns, if you're unsure what this exactly is I'd recommend reading the article I wrote here. It talks about decomposition patterns mentioning what component-based decomposition is. In this chapter, we'll go through a technique of patterns that describe the refactoring of monolithic source code to arrive at a set of well-defined components that could eventually become services. The 5-steps are as follows:
Identify and size component pattern
Gather common domain components pattern
Flatten components pattern
Determine component dependencies pattern
Create component domain pattern
Create domain services pattern
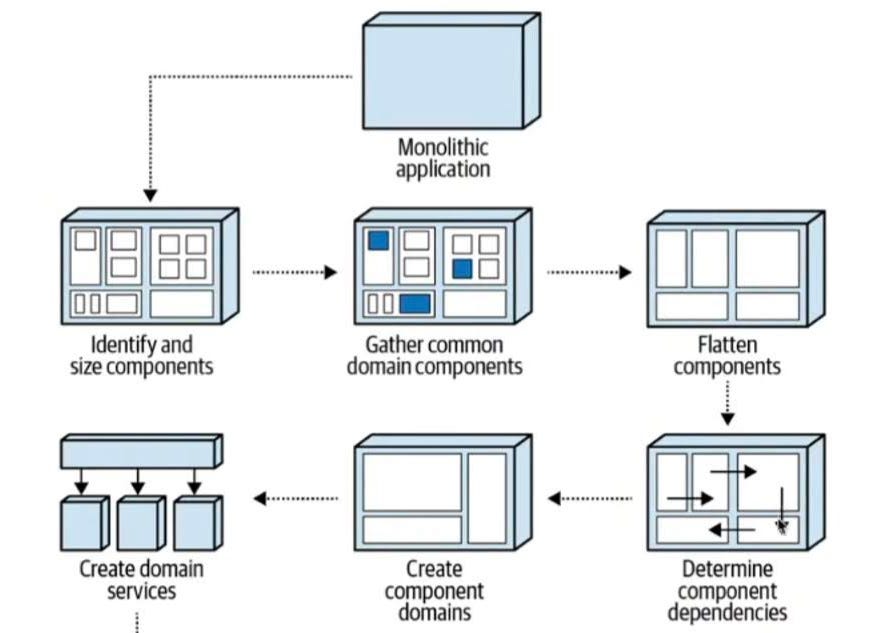
Decomposition Patterns
We'll start by describing each pattern and giving ideas on how to maintain the pattern in the future (adding fitness functions).
Fitness functions are like tests but for software architecture. It's a set of conditions that run against your codebase and alert if any certain architecture design decisions made were violated. Usually run as a CI/CD pipeline.
Identify and Size Components Pattern
Description
Identifying components in the system and sizing them is a critical step in the process. This pattern mainly looks for components that are either too big or too small.
Components that are relatively larger than other components are usually more coupled to other components and are harder to break into separate services. Which leads to a less modular architecture.
Determining the size of components is a difficult task but one useful metric for component sizing is calculating the total number of statements within a given component. A statement is a single action performed by the source code (the ones that usually end in semi-colons in languages such as C).
While not being perfect it's a good indicator of how much the component is doing and how complex the component is.
Having a relatively consistent component size all around is very important.
Statement count per component should be listed in a table-like structure as follows;
| Component name | Component namespace | Percent | Statements | Files |
| Billing Payment | ss.billing.payment | 5 | 4,312 | 23 |
Component name is a descriptive name and identifier of the component that is consistent throughout application diagrams and documentation. The name should be as self-describing as possible. Feel free to change the component name if it doesn't match its function.
Component namespace is the physical identification of the component representing where the source code files implementing that component are grouped and stored.
Components are a bunch of classes, functions, and variables that have high cohesion and are interrelated to each other. They serve to solve a particular problem in the domain. For example, Billing payment handles the payment for the customer, etc.
Percent is the relative size of the component based on its percentage of the overall source code containing that component, helpful in detecting too large or too small components.
Statements are the sum of the total number of source code statements in all source files contained within that component, helpful in not only detecting the size but also the complexity of the component. A component with 12,0000 statements has a high chance of being complex.
Files are the total number of source code files that are contained within the component. This provides additional information about the component from a class structure standpoint. For example, a component with 18,000 statements and only 2 files may be an indicator to refactor into smaller more contextual classes.
When resizing a large component, two main approaches can be taken.
Functional Decomposition (Technical splitting)
Domain-Driven Approach (Domain splitting)
Sometimes components can be split into subdomains that could help create a more modular system.
Fitness Function
Maintain component inventory
This maintains the component structure as is and alerts if any new files are added or removed.
Alert if component code percentage exceeds a certain overall.
This is to maintain the overall evenly sized components.
Gather Common Domain Components Pattern
This pattern is all about identifying and collecting common domain logic and centralizing it into a single component.
Description
Shared domain functionality is part of the business processing logic of an application. Consolidating a common domain helps eliminate duplicate services when breaking apart a monolithic system. The subtle differences between the common domain functionality can be resolved within a single service or library (common code shared).
This is mostly a manual process, Usage of shared classes across components could be a good indicator that common domain functionality exists. Similar functionality scattered along the codebase will need consolidation.
Another way is by looking at the name of the logical component namespaces. For example ss.ticket.audit ss.billing.audit ss.survery.audit all contain audit-related functionality. While they may have different context, the outcome is the same (inserting a row in the audit table). This can be consolidated into ss.shared.audit resulting in less code duplication and fewer services in the resulting distributed architecture.
Fitness Functions
Find common names of leaf nodes of component namespace
This finds components with the same name, might be a good indicator that they can be consolidated into a single component.
Find common code across components.
Helps in detecting duplicated classes in different components which also can be a good indicator.
Flatten Components Pattern
Components are the building blocks of an application. They are usually defined through namespaces or packages in programming languages. However, when components are built on top of other components (nesting), they stop being components per our definition and start losing their identity.
Description
This pattern is used to ensure that components are not built on top of one another but rather flattened and represented as leaf nodes in a directory structure or namespace.
When a new directory gets created in a certain namespace or particular component, that component no longer becomes a component but rather a SUBDOMAIN
For example something like this.
| Component name | Component namespace | Files |
| Survey | ss.survey | 5 |
| Survey Templates | ss.survey.templates | 7 |
While this might make sense from a developer standpoint, isolating the template code from the survey processing. It creates a problem because survey templates would be considered part of the survey component. While we might be tempted to consider templates a subcomponent of the survey, issues arise trying to form services from these components. Should both components reside on a service named survey or should the survey templates be a separate service from the survey one?
This problem is resolved by defining a component as the last node of the namespace or directory structure
With this information. ss.survey.templates is a component but ss.survey will be considered a subdomain or root namespace.
The 5 class files belonging to the survey in the table above are orphaned because they don't belong to a component. Since ss.survey is a subdomain it shouldn't contain any code files.
The Flatten Components Decomposition Pattern is used to move orphaned classes to create well-defined components that exist only as leaf nodes of a directory or namespace.
The direction of flattening depends on you entirely, should the orphaned classes be moved to the template's component or move the template's source code up to the survey namespace? Maybe also split the survey orphaned code into several components instead.
Regardless of the direction of flattening, make sure source code files reside only in leaf node namespaces or directories so that source code can always be identified within a specific component.
Root namespace is a namespace node that has been extended by another namespace. For example, survey is a root namespace because it was extended by templates.
Fitness Functions
No source code should reside in a root namespace (subdomain)
Checks for any orphaned code files and alerts if any.
Determine Component Dependencies Pattern
The most asked questions when migrating from a monolithic application are how feasible it is to break it apart, the rough overall effort of the migration and whether will it require a rewrite or a refactor of the code.
Description
The purpose of this pattern is to determine and analyze the incoming (afferent) and outgoing (efferent) dependencies between components (coupling) to determine what the resulting service dependency graph might look like after breaking apart the application.
Trying to determine the granularity of a service is a very difficult process because every component potentially is a candidate that's why it's crucial to understand the dependencies between components.
Components that have minimal or no coupling are amazing candidates for splitting since they are functionally independent of other components.
When breaking apart monolithic applications, visual diagrams are very important because they act as a radar from which to determine where the enemy (high coupling) is located. Also, give an idea of what the dependency matrix will look like.
Identifying and understanding the coupling between components is essential for the success of monolithic migration. Gives the architect the feasibility estimate as well.
It also gives the architect dependency refactoring opportunities before breaking apart the application. If something could be done better why not!
Total coupling is the sum of both afferent and efferent coupling. Sometimes breaking apart a component can decrease the coupling level depending on which parts of the component code are highly used in other components.
Fitness Functions
No component shall have more than <some number> of total dependencies
This controls the overall level of coupling and notifies the architect if an attempt to exceed the number was made.
<some component> should not have a dependency on <another component>
This restricts certain components from having dependencies on each other
Create Component Domains Pattern
While each component can be identified as a separate service, the relationship between services and components is a one-to-many relationship. A service granularity can be fine, or coarse depending on its functionality or domain.
Description
The purpose of this pattern is to logically group components so that more coarse-grained domain services can be created when breaking up an application.
This pattern is a very efficient way of determining what will eventually become a service in a distributed architecture.
Component domains are physically manifested in application source code through the use of namespaces, because namespaces are hierarchical they become a great way to represent the domains and subdomains of functionality.
Coarse-grained services are usually a great stepping stone when migrating to microservices, let's look at the table below;
| Component | Namespace |
| Billing Payment | ss.billing.payment |
| Billing History | ss.billing.history |
| Customer Profile | ss.customer.profile |
| Support Contact | ss.supportcontact |
As you may notice they are all customer-related functionality, Their namespaces however don't reflect this. So if we group them under a customer namespace consolidating these components into a single coarse-grained domain that potentially can be made into fine-grained services in the future is a great start.
| Component | Namespace |
| Billing Payment | ss.customer.billing.payment |
| Billing History | ss.customer.billing.history |
| Customer Profile | ss.customer.profile |
| Support Contact | ss.customer.supportcontact |
Fitness Functions
All namespaces under <root namespace node (subdomain)> should be restricted to <list of domains>
This prevents additional domains from being inadvertently created by development teams and alerts the architect if any new namespaces are created outside of the approved list of domains.
Create Domain Services Pattern
Once components have been sized, flattened and grouped into domains, the domains can then be moved into separately deployed domain services.
Domain services are coarse-grained, separately deployed units of software containing all of the functionality for a particular domain.
Description
In the simplest form, Service-based architecture consists of a user interface that remotely accesses coarse-grained domain services all sharing a single monolithic database
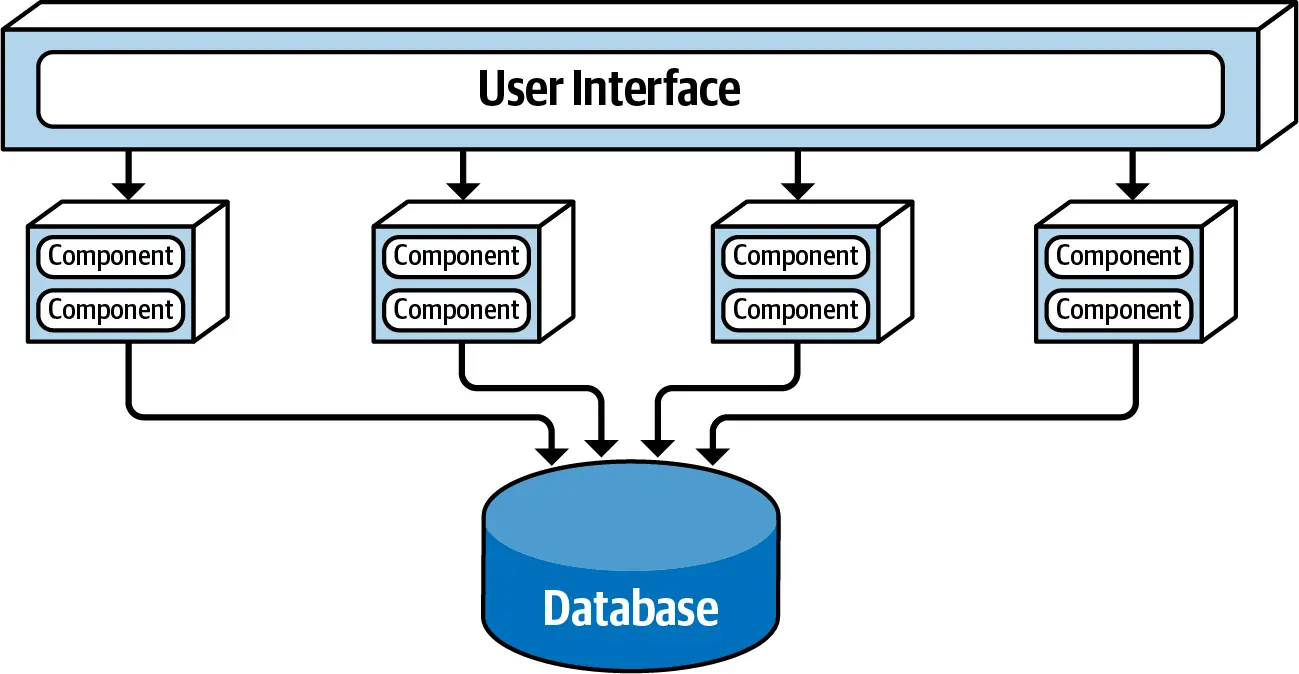
This step also helps the architect understand each domain separately and decide whether to break the domain further into finer-grained services.
Starting as fine-grained services is a trap because it could cause unneeded distributed workflows, and distributed transactions which are potential headaches that are avoided when possible.
The architect should make sure all components are identified and refactored before moving forward with this step. This helps in preventing future potential headaches in editing/moving different components.
Fitness Function
All components in <some domain service> should start with the same namespace
Easier readability and understanding of grouped domain components.
Summary
The described decomposition patterns provide a structured, controlled and incremental approach for breaking apart monolithic architectures. Stay tuned for the next chapter which goes hand in hand with this one, data decomposition!
That's been it for this article. Till the next one! 😊




